SRNAFNet
 Low-Res (top-left),
High-Res (top-right),
Bicubic (bottom-left),
SRNAFNet (bottom-right)
Low-Res (top-left),
High-Res (top-right),
Bicubic (bottom-left),
SRNAFNet (bottom-right)
SRNAFNet is a convolutional neural network (CNN) developed and trained to produce high-resolution images from low-resolution inputs. More generally speaking, it performs x2 upscaling on RGB images.
For the sake of reading, I won’t explain every detail of the network and the results. This page justs serves as a realistic summary of what was developed.
Reason
This project was developed mainly for the purpose of fulfilling the final project requirements of two different classes I was taking during my final semester of university. The project was developed as a team and I had the primary responsibility of model development.
I wasn’t too interested in machine learning problems at the start, only having toyed with it a year prior (2024). However, developing this project made me far more interested in computer vision problems specifically and much of the research going on behind it.
Model
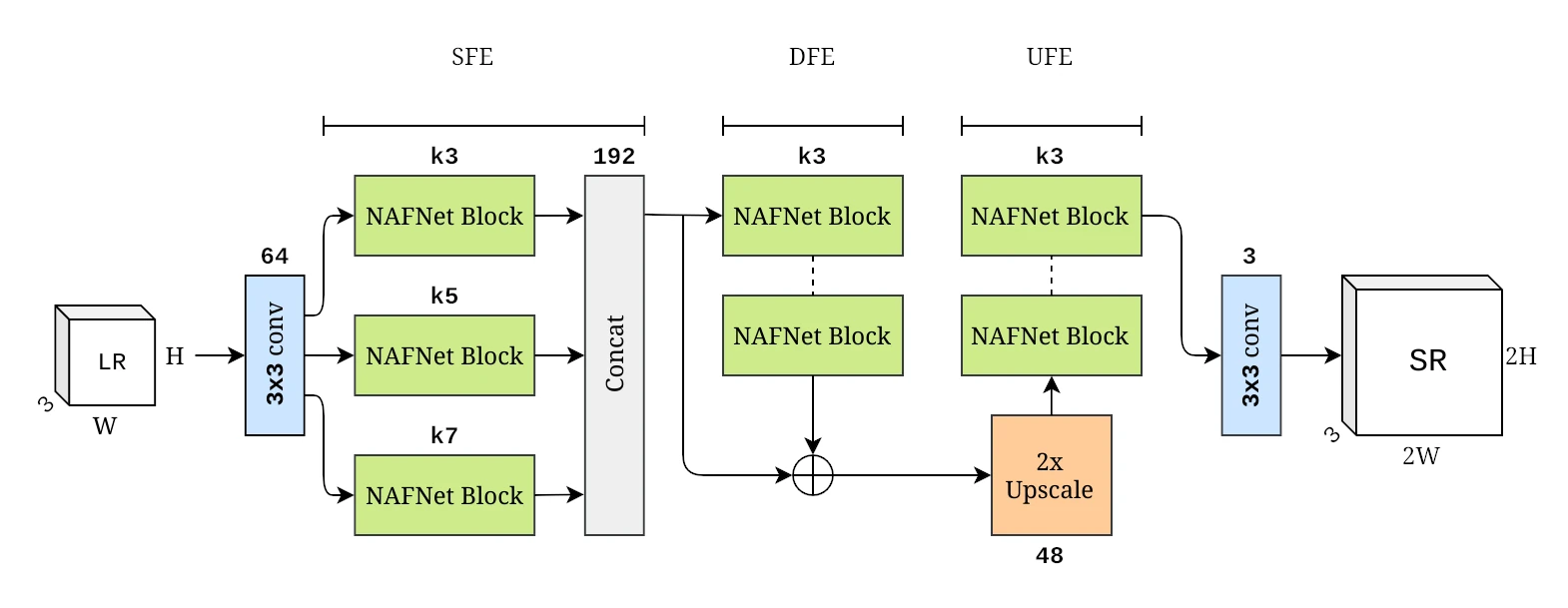 SRNAFNet Architecture
SRNAFNet Architecture
The model is essentially a combination of two works, a multi-path progressively upscaling GAN from this work and the intra-block architecture known as the NAFNet block from this work.
Some modifications were made to make them fit our situation, namely cutting off the final upscaling stage from the original network which made it upscale to x4, removing the GAN componenet, and some adjustment to kernel sizes of the NAFNet block.
Why these works? Well we were mainly interested in the NAFNet block which, to be more specific, is a transformer style block that adjusts the channel attention component and nonlinear activation functions with simpler constructions that don’t have nonlinear activation functions. Hence the name NAFNet for Nonlinear Activation Free Network (block). NAFNet was noted as performing very well in denoising and stereo super resolution (SSR) so we wanted to try it for SISR.
Since NAFNet is based on a U-Net style architecture which isn’t commonly used in SISR, we needed to adopt a different architecutre. That’s where the other work came from. There wasn’t too much of a reasoning for it, it just looked good to us.
Experiments and Results
The model was trained on a combination of the DIV2K training set and Flickr2K dataset, and validation was performed on the DIV2K validation set. Low-resolution images were acquired with on the fly bicubic downscaling. Patch size at 128px, batch size of 16, 20000 iterations, L1 loss, Adam optimizer, and learning rate of 1e-3 to 1e-7 using cosine annealing.
For evaluation, we measured PSNR and SSIM on four benchmark datasets: Set5, Set14, BSD100, and Urban100. For some comparative analysis, we also implemented variations of the network which utilized the other intra-block architectures discussed in the NAFNet paper.
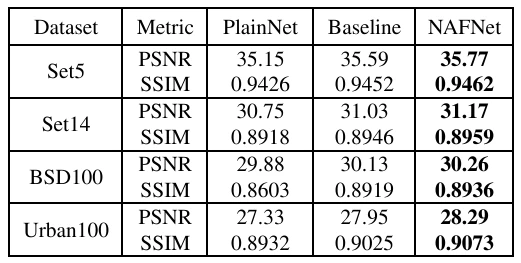 PSNR and SSIM metrics of each block type
PSNR and SSIM metrics of each block type
The NAFNet style block performed the best out of all intra-block architectures in PSNR and SSIM metrics. This was also the case in the NAFNet paper but it’s nice to see it carry over in a similar but different case.
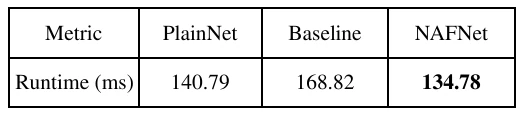 Average per-image inference time for x2 downscaled images from Urban100
Average per-image inference time for x2 downscaled images from Urban100
Surprisingly, the NAFNet block also performed the best amongst all variations on inference time. Even though PlainNet lacks the two layer normalizations and channel attention mechanism found in Baseline and NAFNet, it still performs worse than NAFNet, albeit marginally.
Overall, the network performs alright. I mean it’s not up to state-of-the-art performance which really comes down to a lot of factors that we didn’t really have the time to test. More training time and a deeper network could have gotten it to a much stronger state. Maybe another day where I have more than 8GB of VRAM will I try that out.
Future?
More training? Deeper network? Different architecture? More upscaling? GAN? All of that seems pretty good.